For the following data, what would be the correct attribute/value oair to use to successfully extract the correct timestamp from all the events?
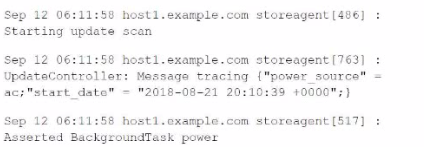
A. TIMK_FORMAT = %b %d %H:%M:%S %z
B. DATETIME CONFIG = %Y-%m-%d %H:%M:%S %2
C. TIME_FORMAT = %b %d %H:%M:%S
D. DATETIKE CONFIG = Sb %d %H:%M:%S
Explanation:
The correct attribute/value pair to successfully extract the timestamp from the
provided events is TIME_FORMAT = %b %d %H:%M:%S. This format corresponds to the
structure of the timestamps in the provided data:
Which of the following are default Splunk Cloud user roles?
A. must_delete, power, sc_admin
B. power, user, admin
C. apps, power, sc_admin
D. can delete, users, admin
Explanation: Default Splunk Cloud roles include power, user, and admin, each with unique permissions suitable for common operational and administrative functions.
Files from multiple systems are being stored on a centralized log server. The files are organized into directories based on the original server they came from. Which of the following is a recommended approach for correctly setting the host values based on their origin?
A. Use the host segment, setting.
B. Set host = * in the monitor stanza.
C. The host value cannot be dynamically set.
D. Manually create a separate monitor stanza for each host, with the nose = value set.
Explanation: The recommended approach for setting the host values based on their origin when files from multiple systems are stored on a centralized log server is to use the host_segment setting. This setting allows you to dynamically set the host value based on a specific segment of the file path, which can be particularly useful when organizing logs from different servers into directories.
What two files are used in the data transformation process?
A. parsing.conf and transforms.conf
B. props.conf and transforms.conf
C. transforms.conf and fields.conf
D. transforms.conf and sourcetypes.conf
Explanation: props.conf and transforms.conf define data parsing, transformations, and routing rules, making them essential for data transformations.
Which of the following is a correct statement about Universal Forwarders?
A. The Universal Forwarder must be able to contact the license master.
B. A Universal Forwarder must connect to Splunk Cloud via a Heavy Forwarder.
C. A Universal Forwarder can be an Intermediate Forwarder.
D. The default output bandwidth is 500KBps.
Explanation: A Universal Forwarder (UF) can indeed be configured as an Intermediate
Forwarder. This means that the UF can receive data from other forwarders and then
forward that data on to indexers or Splunk Cloud, effectively acting as a relay point in the
data forwarding chain.
Option A is incorrect because a Universal Forwarder does not need to contact the
license master; only indexers and search heads require this.
Option B is incorrect as Universal Forwarders can connect directly to Splunk Cloud
or via other forwarders.
Option D is also incorrect because the default output bandwidth limit for a UF is
typically much higher than 500KBps (default is 256KBps per pipeline, but can be
configured).
What information is identified during the input phase of the ingestion process?
A. Line breaking and timestamp.
B. A hash of the message payload.
C. Metadata fields like sourcetype and host.
D. SRC and DST IP addresses and ports.
Explanation: During the input phase, Splunk assigns metadata fields such as sourcetype, host, and source, which are critical for data categorization and routing.
| Page 1 out of 14 Pages |
Contact Us - Privacy Policy ... Copyright © - All Rights Reserved